9초 걸리던 PDF, 화면 캡처를 걷어냈다
단순 최적화가 아니라 구조 자체를 바꿔야 했던 이유. 왜 화면 캡처가 근본적으로 틀린 접근이었는지, 왜 SQS + 워커였는지.
9초 걸리던 PDF, 화면 캡처를 걷어냈다
처음 받은 시스템의 구조
입사하고 리포트 생성 기능을 처음 확인했을 때 구조는 이랬다.
사용자 → 업로드 요청
→ 클라이언트 화면 이동 (결과 화면 A → B → C → ...)
→ 각 화면마다 스크린샷 생성 → S3 업로드
→ 모든 이미지를 모아서 Python 서버가 PDF로 합침
→ 완료 응답 반환
한 건의 리포트를 만드는 데 최대 9초 이상 걸렸다. 검사를 마친 환자와 보호자가 기다리는 동안 의료진은 그냥 스크린을 바라봤다.
VOC가 쌓이기 시작했다. "리포트 출력이 왜 이렇게 느리냐"는 민원이 반복됐다.
왜 "최적화"가 아니라 "구조 변경"이었나
처음에는 Python 서버 튜닝이나 이미지 압축 같은 방향을 떠올릴 수 있었다. 실제로 그 방향을 먼저 검토했다.
그런데 분석해 보니 병목이 한 곳에 있는 게 아니었다. 데이터 하나가 PDF가 되기까지 거치는 단계마다 비용이 붙었다. 화면을 이동할 때마다 렌더링을 기다리고, 그 화면을 스크린샷으로 찍고(CPU와 메모리), 이미지를 S3에 올리고, Python 서버가 그걸 다시 내려받고(네트워크 I/O가 화면 수만큼 왕복), 마지막에 이미지들을 PDF로 합친다. 화면이 10개면 S3 업로드와 다운로드가 각각 10번씩 발생한다. 이걸 "최적화"한다는 건 각 단계를 조금씩 줄이는 건데, 구조 자체가 비효율의 원인이면 그렇게 깎아봐야 한계가 뻔하다.
근본 문제는 화면 캡처 방식 그 자체였다.
뜯어보면 좀 황당한 구조였다. 리포트에 박혀야 할 데이터는 이미 우리 DB에 멀쩡히 정규화돼 있었다. 그런데 시스템은 그 데이터를 굳이 브라우저 화면에 렌더링한 뒤, headless 브라우저로 스크린샷을 찍어 이미지로 만들고, 그 이미지를 S3에 올렸다가 Python 서버가 다시 내려받아 PDF로 합치고 있었다. DB에 답이 다 있는데 화면을 한 바퀴 빙 돌아 이미지로 찍고 다시 합치는, 그 한 바퀴가 9초의 정체였다. 데이터는 이미 있는데 굳이 화면을 경유할 이유가 없었다.
그래서 뭘로 바꿀까
구조를 바꾸기로 하고 나니, 이번엔 어떤 방식으로 비동기를 만들지가 문제였다.
제일 먼저 떠오른 건 그냥 백그라운드 스레드로 처리하는 거였다. 요청 받으면 스레드 하나 띄워서 처리하고 응답만 먼저 주는 식. 그런데 서버가 재시작되거나 죽으면 처리 중이던 리포트가 그대로 증발한다. 의료 플랫폼에서 리포트 유실은 그냥 넘어갈 문제가 아니다. 동시 요청이 몰리면 스레드가 폭발하는 것도 걸렸다.
배치 스케줄러도 생각해봤다. 주기적으로 미처리 리포트를 모아 한 번에 생성하는 방식. 안정적이긴 한데, 요청하고 다음 배치 주기까지 기다려야 한다. "생성 누르면 곧 나와야 한다"는 현장 요구랑 정면으로 부딪혔다.
결국 남은 게 메시지 큐 + 워커였다. 요청을 큐에 넣어두면 서버가 재시작돼도 메시지는 큐에 남아 있고(내구성), 워커 수를 조절해 처리량도 맞출 수 있고(확장성), 요청자는 큐에 넣자마자 응답을 받는다(응답성). 내가 필요했던 세 가지를 동시에 만족하는 건 이 방식뿐이었다.
큐는 SQS로
MQ 중에서는 SQS를 골랐다. 서버가 재시작돼도 메시지가 큐에 살아 있고, 요청하면 바로 응답이 나가야 한다는 게 가장 큰 포인트였다. 요청을 받는 쪽은 워커가 하나라 꺼내 쓰면 돼서, Kafka처럼 한 이벤트를 여러 컨슈머가 나눠 받는 fan-out 구조까지는 필요 없었다. 다만 완성된 리포트를 알리는 쪽은 사정이 좀 달랐는데, 그건 뒤에서 다룬다.
바꾼 구조
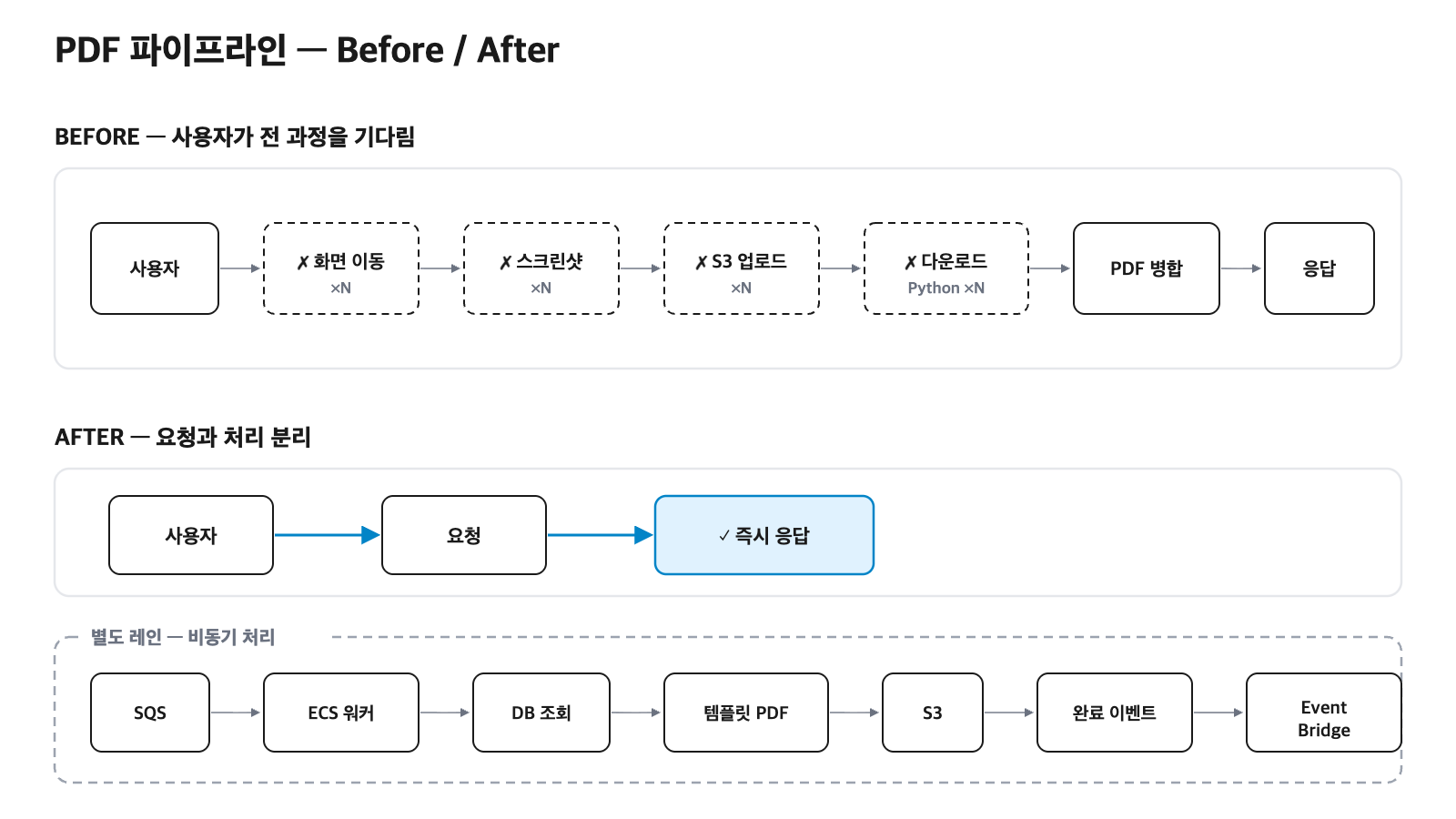
EventBridge 뒤의 완료 알림 fan-out은 아래에서 따로 다룬다. 사용자는 나중에 리포트 조회 버튼을 누르면 S3에서 완성본을 바로 받는다.
핵심은 두 가지다.
- 리포트 생성 요청과 리포트 조회를 완전히 분리했다.
- 화면 캡처를 제거하고 DB 데이터를 직접 읽어 PDF를 만들었다.
완료 알림은 EventBridge + SNS로
워커가 PDF를 만들어 S3에 올리면 거기서 끝이 아니었다. "이 리포트 완성됐다"는 사실을 알아야 하는 쪽이 더 있었다. 의료진에게 알려줘야 했고, 리포트 완성에 맞물려 돌아가는 다른 서비스도 있었다.
그래서 워커는 업로드를 마치면 완료 이벤트를 하나 발행한다. EventBridge가 이 이벤트를 받아 라우팅하고, SNS가 구독자들에게 뿌린다. 의료진 통지로 한 갈래, 그 이벤트가 필요한 타 서비스로 또 한 갈래.
앞에서 요청 큐를 SQS로 고른 거랑 여기서 갈린다. 요청은 워커 하나가 꺼내 쓰면 되는 1:1이라 SQS가 맞았다. 반면 완료 알림은 받아야 할 데가 여럿인 1:N이고, 한 이벤트를 여러 구독자에게 뿌리는 건 SNS의 일이다. 같은 "메시지를 전달한다"는 작업인데 한쪽은 점대점, 한쪽은 발행-구독이라 도구가 갈린 거다.
진짜 복병은 HTML 템플릿이었다
구조를 워커로 바꾸는 건 설계대로 밀면 그만이었는데, 정작 시간을 잡아먹은 건 엉뚱하게도 PDF 레이아웃이었다. 기존엔 화면을 그대로 찍었으니 백엔드가 레이아웃을 신경 쓸 일이 없었다. 화면 캡처를 걷어낸 순간, 항목 많고 표·그래프가 빽빽한 그 의료 결과지를 순수 HTML/CSS 템플릿으로 처음부터 다시 깎아야 했다.
특히 PDF 변환 엔진(Puppeteer 계열)의 페이지 브레이크가 골칫거리였다. page-break-inside를 잡아주지 않으면 표가 페이지 경계에서 잘리고, 그래프가 반토막 난 채 다음 장으로 넘어갔다. 인쇄물이라 한 칸만 밀려도 티가 났다. 결국 SQS 워커를 짜는 시간보다 이 템플릿 마진과 페이지 경계를 맞추는 데 시간을 훨씬 많이 썼다.
트레이드오프: 즉시 응답 vs 폴링
이 구조의 트레이드오프는 명확하다. 사용자가 "리포트 생성" 버튼을 누른 직후에는 PDF가 없다. 워커가 처리를 끝낸 뒤에야 다운로드할 수 있다.
이걸 처리하는 방법으로 두 가지를 검토했다.
방법 A: 폴링 (Polling). 클라이언트가 주기적으로 "리포트 준비됐어?" API를 호출하는 방식이다. 구현은 단순하지만 불필요한 요청이 반복된다.
방법 B: 상태 기반 조회. "리포트 조회" 버튼을 누를 때 S3에 파일이 있으면 다운로드, 없으면 "생성 중" 메시지를 보여주는 방식이다.
플랫폼 사용 패턴을 보니 리포트 생성 후 바로 다운로드하는 게 아니라 검사 마무리 상담을 한 뒤 다운로드하는 경우가 많았다. 그 사이에 워커가 처리를 끝낸다. 폴링 없이 상태 기반 조회만으로 충분했다. 폴링을 따로 두지 않은 대신, 리포트가 완성됐다는 사실 자체는 앞의 SNS 알림으로 의료진에게 전달됐다.
결과
가장 크게 바뀐 건 사용자가 기다리지 않게 됐다는 점이다. 전엔 생성 버튼을 누르면 9초 넘게 화면이 멈춰 있었는데, 이제는 누르는 즉시 다음으로 넘어간다. 생성은 백그라운드 워커가 맡고, PDF 자체도 화면 캡처를 걷어낸 덕에 9초에서 1.5초로 줄었다(83% 단축). 화면 수만큼 반복되던 S3 업로드도 최종 PDF 한 번으로 끝나고, 요청마다 Python 서버를 점유하던 부하도 워커로 분산돼 피크 타임에도 큐잉으로 버틴다.
체감은 현장에서 더 분명했다. 의료진 입장에선 생성 버튼을 누르면 바로 다음 화면으로 넘어가고, 환자와 상담을 마친 뒤 다운로드를 누르면 리포트가 그 자리에서 나온다. 9초 동안 모니터만 바라보며 환자를 기다리게 하던 장면이 사라졌다. 반복되던 "출력이 왜 이렇게 느리냐"는 VOC도 거의 끊겼다.
마무리
하나 짚어두고 싶은 게 있다. 9초가 1.5초가 된 걸 보고 MQ가 속도를 만들어줬다고 읽기 쉬운데, 그게 아니다. MQ는 속도 자체를 빠르게 하는 도구가 아니라 요청과 처리를 떼어놓는 도구다. 이 시스템은 요청을 논블로킹으로 받고 백그라운드 워커가 따로 작업해야 했고, 그래서 앞단에 큐가 필요했던 것뿐이다. 빨라진 진짜 이유는 화면 캡처를 걷어낸 데 있었다.
그래서 같은 SQS인데도, 규모가 작아 오히려 큐를 걷어낸 적도 있다. 그땐 월 수백 건짜리 워크로드라 DB 한 테이블로 충분했고, 이번엔 요청과 무거운 생성을 떼어놓을 큐가 필요했다. 도구를 먼저 정해놓고 끼운 게 아니라, 워크로드가 도구를 정했다.
9초가 1.5초가 된 숫자보다, 화면을 경유할 이유가 없다는 걸 알아챈 게 이 일의 핵심이었다.